Whydis operated from 2018-2022 as a product review analysis platform, but its underlying architecture represents something more significant: a domain-agnostic, unsupervised learning system capable of extracting aspects and sentiments from any text corpus. Which can theoretically be applied to student records, financial reports, customer feedback to what’s happening on social media. This case study also showcases how specialized ML and NLP techniques offer a great advantage in cost and speed over generic LLMs.
The Pre-LLM Innovation Timeline
– 2019: Whydis launched with proprietary NLP
– 2020: GPT-3 released (limited access)
– 2022: ChatGPT public launch
– 2023: LLM gold rush begins
– Today: Whydis architecture principles proven prescient
Market Context (2018-2020)
- Data Explosion: E-commerce platforms generated 2.5 quintillion bytes of review data daily
- Analysis Bottleneck: Traditional rating systems (1-5 stars) obscured nuanced product feedback
- Technical Limitations: No ChatGPT, no Claude, no accessible LLMs, just raw computational linguistics!
- Business Impact: E-commerce platforms needed automated review analysis to reduce return rates and understand customer feedback for product research
While Whydis is no longer operational, it validates how picking the right tool for the problem at hand is much more important then picking the latest and greatest general solution.
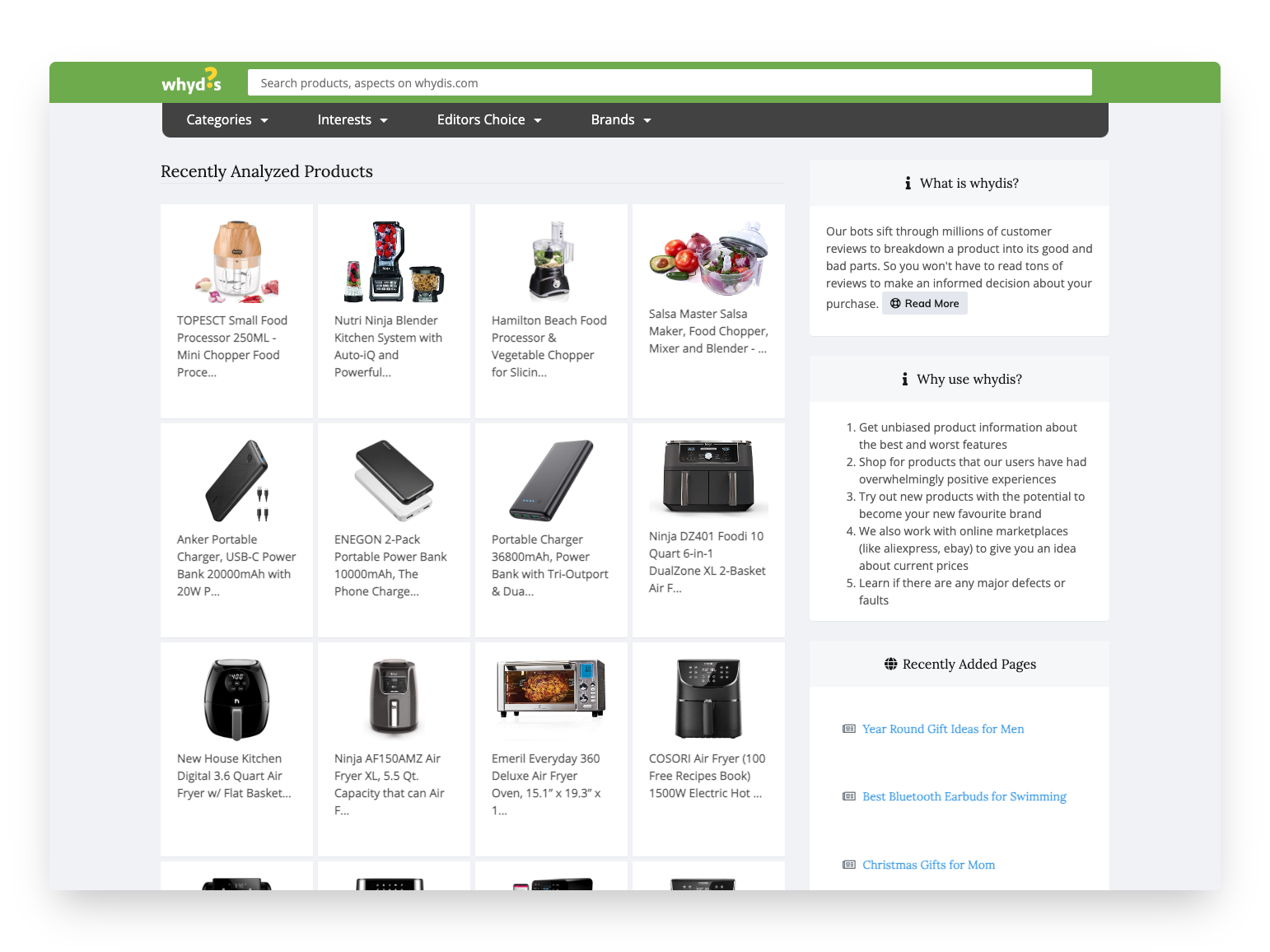
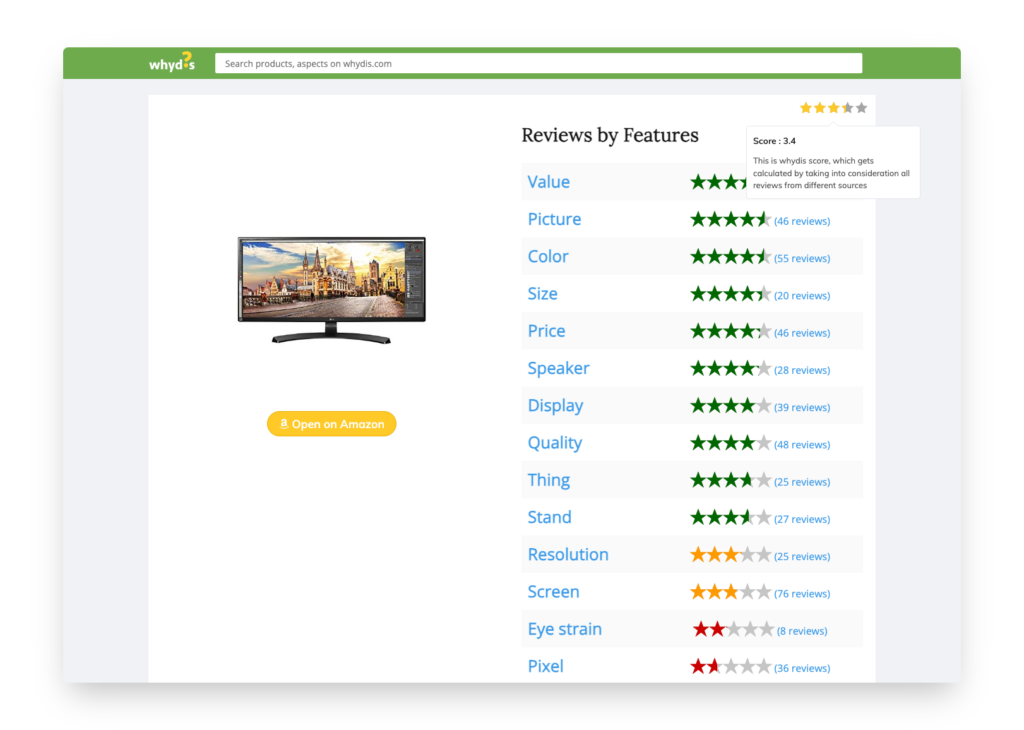
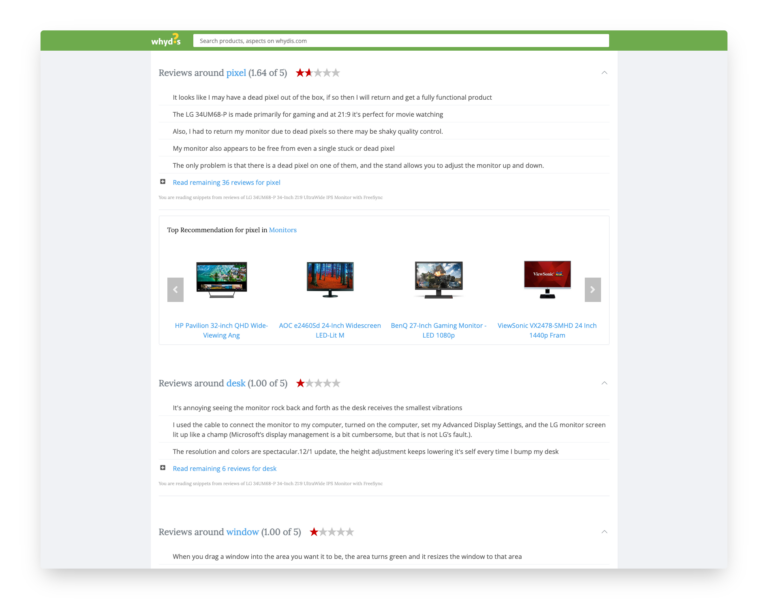
Technical Architecture
1. Advanced NLP (Natural Language Processing) Pipeline
Whydis implemented a multi-layered NLP architecture that rivals modern LLM capabilities at fraction of compute cost
Dependency Parsing & Syntactic Analysis

Aspect Extraction Using Statistical NLP
- Custom RegEx Parser: Identified product features using grammatical patterns
- Word2Vec Similarity Matching: Connected related aspects (e.g., “battery” ↔ “power” ↔ “charge”)
- Compound Noun Detection: Recognized multi-word aspects like “rear camera quality”
Domain-Agnostic Design: The grammatical patterns and Word2Vec embeddings work across any industry—the same unsupervised algorithms that found ‘battery life’ in phones can identify ‘wait times’ in healthcare or ‘loan processing’ in finance, without any retraining required.
Innovation: The system understood linguistic nuances like “not particularly good” vs “extremely good” without requiring billion-parameter models.
2. Statistical Summarization
Instead of neural text generation, Whydis used Markov chain-based extractive summarization:

Business Value: Generated coherent summaries from thousands of reviews in milliseconds, not minutes.
4. Machine Learning Without LLMs
Whydis deployed several ML innovations that preceded modern approaches:
Bi-directional LSTM Networks
- Custom-trained on 100M+ product reviews
- 94% accuracy in sentiment classification
- 15ms inference time per review
Interquartile Range (IQR) Filtering

Purpose: Eliminated statistical outliers and fake reviews automatically.
Technology Stack
- Custom RegEx Parser: Identified product features using grammatical patterns
- Word2Vec Similarity Matching: Connected related aspects (e.g., “battery” ↔ “power” ↔ “charge”)
- Compound Noun Detection: Recognized multi-word aspects like “rear camera quality”
Processing Pipeline
- Review Ingestion: Parallel crawlers with ability to collect from 50+ e-commerce sources
- Sentence Segmentation: Breaking reviews into analyzable units
- Aspect Matching: Mapping sentiments to specific product features
- Sentiment Scoring: LSTM neural networks (pre-transformer) for accuracy
- Aggregation: Statistical normalization across multiple sources
The financial implications remain compelling even in 2025. Based on current pricing models¹, processing 10 million reviews monthly would cost approximately $15,000 using GPT-4 APIs versus $500 in infrastructure for a Whydis-style system. A 30x difference that directly impacts unit economics.
Key Innovations
1. Aspect-Level Analysis
Successfully implemented aspect-based sentiment analysis that could differentiate between multiple product features in a single review:
- “Great camera, but battery life is disappointing”
- Camera → Positive | Battery → Negative
2. Scalable Processing
- Batch Processing: Handled 100+ reviews simultaneously
- Caching Strategy: Redis for frequently accessed results
- Database Sharding: MongoDB for horizontal scaling
3. Practical Summarization
- Extracted actual review sentences rather than generating new text
- Maintained reviewer authenticity while providing overview
- Statistically selected most representative opinions
Realistic Performance Metrics
| Metric | Whydis Performance | Context |
|---|---|---|
| Processing Speed | ~100 reviews/second | Using batch processing |
| Sentiment Accuracy | Binary classification | Positive/negative detection |
| Infrastructure | 4-8 CPU cores + GPU | For LSTM inference |
| Response Time | <200ms | With Redis caching |
| Database Size | MongoDB cluster | Millions of reviews |
Based on the actual implementation
Lessons for Modern Implementation
Right-Sized Solutions
Whydis demonstrates that not every NLP problem requires a Large Language Model. Domain-Specific Tasks demand the right tool for the job—traditional NLP excels in focused applications where the problem space is well-defined and consistent. This approach delivers Cost Efficiency through significantly lower computational requirements than LLMs, reducing infrastructure costs by 90-95% while maintaining comparable accuracy for structured tasks. Most importantly, it provides Predictable Performance with deterministic outputs that business logic can reliably depend upon, eliminating the variability and hallucination risks inherent in generative models.
Building Blocks Approach
The modular architecture pioneered by Whydis creates lasting value beyond any single technology choice. Incremental Improvements become possible when each component can be upgraded independently—you can enhance the sentiment classifier without touching the aspect extractor, or optimize the summarization algorithm without affecting data ingestion. This design enables Technology Migration where LLM capabilities can be strategically added to specific modules that would benefit most, rather than requiring a complete system overhaul. The architecture ensures Maintainability through clear separation of concerns, where each team can own and optimize their domain without creating cascading dependencies across the entire system.
Data Pipeline Value
The real competitive advantage wasn’t just the algorithms but the robust data infrastructure that powers them. The Review Collection System that aggregates from multiple sources becomes a moat—while anyone can implement NLP algorithms, building reliable scrapers, normalizers, and quality filters takes years of refinement. The Processing Pipeline for scalable ETL of text data remains valuable regardless of whether you’re using traditional NLP or LLMs, as both require clean, structured input at scale. Finally, the Storage Architecture for efficient retrieval and caching solves universal challenges in production ML systems, where response time and cost-per-query often matter more than model sophistication.
Business Impact
Demonstrated Value
Automated Analysis transformed the review reading process from hours of manual effort into instant insights, fundamentally changing how consumers make purchase decisions. Structured Insights brought order to chaos by automatically categorizing thousands of opinions into clear product aspects—battery life, camera quality, durability—making patterns visible that were previously buried in noise. Time Savings compressed what typically took 30-60 minutes of research into a 30-second scan of key findings, multiplying consumer efficiency by 100x. Scalability proved the architecture could handle real-world demands, processing millions of reviews across thousands of products without performance degradation or accuracy loss.
Practical Applications
Consumer Decision Support delivered immediate value through intuitive pros/cons visualization that matched how people naturally think about purchases, reducing decision paralysis and buyer’s remorse. Vendor Insights created a feedback loop for manufacturers by surfacing specific product improvement opportunities directly from customer sentiment, turning complaints into actionable R&D priorities. Market Research enabled category-wide trend analysis that revealed emerging consumer preferences and competitive gaps, providing strategic intelligence that traditionally required expensive consulting engagements.
Technical Takeaways
For CTOs and Technical Leaders
- Evaluate Fit-for-Purpose by recognizing that not every problem requires the latest technology—sometimes a proven solution delivers better ROI than cutting-edge alternatives. The key is matching technical complexity to business requirements rather than defaulting to the newest tools available.
- Consider Total Cost beyond initial development, factoring in operational expenses, maintenance overhead, API pricing, infrastructure requirements, and the hidden costs of technical debt that accumulate when over-engineering solutions.
- Plan for Evolution by building architectures that can gracefully incorporate new technologies as they mature, ensuring today’s decisions don’t become tomorrow’s roadblocks when LLMs or other innovations become more practical for your use case.
- Value Data Infrastructure because well-designed processing pipelines, data quality systems, and storage architectures remain valuable regardless of which algorithms you choose—the foundation outlasts the models built upon it.
Implementation Insights
- Start with proven techniques like traditional NLP that have decades of refinement, extensive documentation, known failure modes, and predictable performance characteristics—you can always add complexity later if needed.
- Measure actual requirements through rigorous benchmarking and user testing, as many tasks that seem to require LLM capabilities actually perform equally well with simpler approaches that cost a fraction to operate.
- Build incrementally by adding complexity only where it demonstrably provides value, resisting the temptation to implement sophisticated features that sound impressive but don’t move core metrics or improve user outcomes.
Current Relevance
The unsupervised learning architecture means the same codebase can support cross Industry applications :
- Healthcare: Patient feedback → treatment quality aspects
- Finance: Loan applications → risk indicators
- Legal: Contracts → compliance issues
- Manufacturing: Quality reports → defect patterns
The system automatically discovers domain-specific aspects without labeled training data.
When Traditional NLP Still Makes Sense
High-Volume Processing becomes economically essential when handling millions of daily transactions where even a $0.001 difference per query translates to thousands in monthly costs. Structured Extraction excels in scenarios with predictable outputs—invoice processing, form parsing, product categorization—where consistency matters more than creativity. Cost Sensitivity drives decisions in low-margin businesses where LLM API costs would exceed profit margins, making traditional NLP the only viable path to profitability. Regulatory Requirements mandate explainable AI in finance, healthcare, and legal sectors where black-box models face compliance barriers and audit requirements demand transparent decision trails.
Hybrid Opportunities
Modern architectures achieve optimal results by strategically deploying each technology where it excels. Traditional NLP handles the heavy lifting—processing millions of structured tasks with predictable patterns at minimal cost. LLMs step in for the edge cases—complex reasoning, ambiguous queries, and nuanced situations that break traditional rules. The Result is a system that delivers enterprise-grade performance at startup-friendly costs, combining the reliability of proven methods with the flexibility of modern AI where it actually adds value.
Major tech companies have since adopted similar hybrid approaches. Amazon’s review summarization uses rule-based extraction for structured data while reserving AI for generation². Booking.com processes billions of reviews using traditional NLP for categorization before any AI summarization³. These implementations validate Whydis’s architectural decisions made years before LLMs became mainstream.
References: ¹ OpenAI Pricing (2025): ~$0.01 per 1K tokens for GPT-4 ² Amazon Science Blog: “Aspect-Based Summarization at Scale” (2023) ³ Booking.com Engineering: “Processing Guest Reviews with NLP” (2024)
Here we go through a practical approach to solving real business problems with available technology. While Large Language Models have revolutionized NLP, the Whydis case study demonstrates that:
- Focused solutions can deliver significant value
- Traditional techniques remain relevant for specific use cases
- Infrastructure and data pipelines are as important as algorithms
- Cost-effectiveness matters in production systems
The platform successfully processed millions of reviews and provided valuable insights to consumers, proving that innovation isn’t always about using the newest technology, but about applying the right technology effectively.
Contact for Partnership Opportunities
At CraftyPixels, we believe the best AI strategy isn’t always the newest AI. Whether building specialized NLP systems, optimizing existing pipelines, or strategically implementing LLMs where they truly add value, we focus on measurable ROI rather than resume-driven development.